
進捗報告記事です。
先日、RAGE Shadowverse 2020 Autumnのプレーオフがありました。とても高レベルの白熱した試合ばかりで面白かったのですが、個人的にモヤモヤを抱えてしまいました。
ファイナリストになられた方で何人か社会人の方がいらっしゃって(別に今回に限ったことではないですが)、社会人だから時間が無い!と言い訳している(参照:Shadowverse AI シミュレータ開発構想と勝利への想い)自分に棘が刺さったような想いでした。
アプローチが違うだけで、私もなんとかしようとしている点では同じだと言い聞かせて正気を保てています。
そのおかげでAIシミュレータの開発のモチベーションは高くなっています。ありがたいことです。
目次
工程と進捗
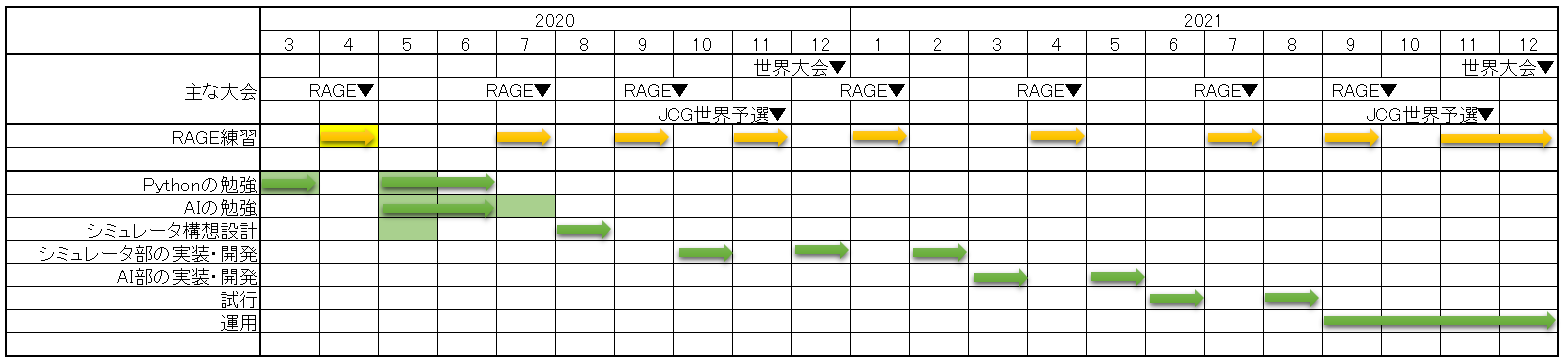 (クリックで画像ファイルに飛びます)
(クリックで画像ファイルに飛びます)
今回のRAGEが、時期的にかなり早くて、私がDay1落ちしたこともあり、7月はそれなりに勉強する時間が持てました。ということで、上の日程表でいうところの7月のところに色を付けています。
やったことは相変わらずAIの勉強なんですが、詳細は後述します。
あとは、やはりシミュレータ開発がしんどいと感じています。これも内容は後述します。「こういう風にやれば実現できそう!」というのが具体的に無いのでちょっと辛いです。
いっそ外注に出すのもありか?なんてことも考えますが、仕様まとめたり、思った通りに作ってもらえる自信がないので、自分で試行錯誤しながらやったほうが金銭的にも時間的にも優しそうと思っています。
AIの勉強進捗
ちょっと前にやったこと:マリガンするAI
5月になるんですが、こんな動画を作りました。
その後AIについて勉強した今の私だと「もっとこうすればよかったかな」というのが浮かんでいます。この動画の結果を出すためにもかなり試行錯誤したので、練習としてはよかったかなと思っています。
最近やったこと:AlphaZeroの勉強
最近はもっぱらAlphaZeroの勉強をしていました。
AlphaZeroとは、こういうものです。
AlphaZero(アルファゼロ)は、DeepMindによって開発されたコンピュータプログラムである。汎化されたAlphaGo Zeroのアプローチを使用している。 2017年12月5日、DeepMindチームはAlphaGo Zeroのアプローチを汎化したプログラムであるAlphaZeroの論文をarXiv上で発表した。AlphaZeroは24時間以内にチェス、将棋、囲碁の世界チャンピオンプログラムであるStockfish、elmo、3日間学習させたAlphaGo Zeroを破るレベルに達した。AlphaZeroは、オープニングブック(序盤定跡データベース)とエンドゲームの表(終盤を解析したデータベース)を参照せずに、4時間の自己対戦だけでStockfishを凌駕した。
それまでチェスおよび将棋のAIで一般的であったアルファ・ベータ探索ではなく、囲碁AIで成功を収めたモンテカルロ木探索(モンテカルロ法の応用)とディープラーニングをこれらのゲームに対して適用しても強いAIが作れることを実証した。
Wikipedhiaより引用
要するに、囲碁や将棋、オセロ、チェスといった2人で対戦する完全情報ゲーム(誰もがゲームに関する情報をすべて把握できるゲーム)における、おそらく現時点最強のゲームAIです。特定のゲームに特化しているわけでじゃなくて、汎用的に強いってのがすごいですよね。
ということで、このAlphaZeroについて勉強していたわけです。
シャドウバースは相手の手札が見えなかったりと不完全情報ゲームなので、そのままは適用できません。とはいえ、AIに関する考え方は適用できる部分は多いはずです。まずはそれを知るところから始めよう、ということで勉強していました。
勉強のために3,4冊ほど本を買いました。一番ためになったなと思ったのがAlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門です。
表紙見て、これは勉強になりそう!と思った
連休はこれで遊ぶ感じかな pic.twitter.com/5Xy0p5H8xy
— あいいろのもち (@mochida_aiiro) July 24, 2020
実際の3目並べや動物将棋みたいな簡単なゲームにAlphaZeroの考え方を適用して、実際にプログラミングするような実践向きな構成になっています。かなり良い本でした。ぶっちゃけ、AlphaZero関連で買う本はこれ1冊だけでよかったなと思いました。。(一番最近買った本がこれ、早く出会いたかったorz)
この本で勉強してから、なんとなく「シャドバシミュレータ側とAIをどんなふうにつなげないといけないか」「シャドバに適用するためには、こういう入力を与えて、こういうアルゴリズムに変えればいいかな」とかもだいぶイメージできるようになったので、一旦AIの勉強は手を止めて、シャドバシミュレータの開発に注力していこうかなと思っています。
おまけ:Google Claboratoryがすごい!
おまけの話です。さきほどの本に書いてあって感動した点を書きます。
AIの学習させるのって、マシンパワーがいるんですよね。なんとなくイメージもってもらえると思います。学習させるのに〇日かかります、的なやつです。
ちょっとパソコンとかに詳しい人なら、GPUという単語を知っているかと思います。実際、AIの学習ではGPUを使うのが主流です(多分)。
そして、AlphaZeroは、GPUよりもさらにAI学習に適したTPUというものを使っているようです。
私が今使っているPCはTPUは当然、GPUすら積んでいません。「そんなんでAIの学習できるの?」という問いに対して素晴らしい回答がありました。
それが、Google Colaboratoryです!
どんなものかというと、WEBブラウザ上で、プログラムを記述(ローカルで作ったものをアップロードしてもOK)して、どこかにあるGPUやらTPUを使わせてもらって、プログラムを動かすことができるんです!無料で!すごくないですか!?
Googleアカウントを持っていれば誰でも使えます。ほんと神サービスです。
とはいえ、連続利用時間制限があったりするのでそのあたりの対応は必要ですが、かなりありがたいですよね。
実行させている様子はこんな感じ。お試しで上の本で記載あったサンプルコードをGPUを使ってAI学習させている様子です。
実際シャドバAIを作って学習させる際は、このGoogle Colaboratory で学習させることになるかなと思っています。
シャドバシミュレータについて今思っていること
誘発処理の汎用化について
処理を発生させるトリガー・条件のようなものをどう構成すればよいのか悩んでいます。
シャドウバースには、「ファンファーレ」「このカードが場にでたとき」「自分のターン開始時」みたいになんらかの条件が成立して効果が発生するものがあります。
上に書いたものはある程度お決まりなのでいいんですが、ものすごく特殊なやつとかの扱いを悩んでいます。例えばこいつとか。
 他にも葬送の回数をカウントして何か効果が誘発されるものがあるなら、葬送をトリガーみたいなものでチェックしようという気になるんですが、《征伐の死帝》のためだけにわざわざ特別に用意してあげないといけないのか?ということです。
他にも葬送の回数をカウントして何か効果が誘発されるものがあるなら、葬送をトリガーみたいなものでチェックしようという気になるんですが、《征伐の死帝》のためだけにわざわざ特別に用意してあげないといけないのか?ということです。
なんなら、《征伐の死帝》に限らず、《フラウロス》とか《天翔けるドラゴニュート》とかもそうです。「〇〇(特定のカード)が場に出るたび」みたいなものもそうです。
おそらく、なんらかのアクションや処理が起きるたびに、今の状態で誘発される効果は無いかをチェックするんでしょうけど、いろんな誘発条件に対して汎用的に対応するベースの仕組みはどんなものがいいんだろう?と頭を抱えているわけです。
書いてて何に悩んでいるのかわからなくなってきました。頭の中で考えるだけじゃ整理できないので、手を動かして試行錯誤してみます。
たぶん、何回かつくっては崩してを繰り返すことになると思います。
スパゲティコードにはしたくないなー
コールバック処理を知った
プログラミングをやっている方だと当たり前の話なのかもしれませんが、ド素人の私は最近知って感動しました。
関数を変数みたいに渡して動的に引き出すタイミング制御できるんですね!と。
シャドバやっていて、ラストワード処理とかすごく謎だったんですよね。
例えば、《テミスの審判》でラストワードを持った2体のフォロワーA、Bを破壊した場合。
プログラミングにさほどなじみのない私の感覚的には、下記が一番最初に思いつく処理順なんです。
フォロワーAが破壊される
→Aのラストワード発動
→フォロワーBが破壊される
→Bのラストワード発動
しかし、シャドウバースではこう処理されています。(厳密には違うかも)
フォロワーAが破壊される
→Aのラストワードが処理待ち状態
→フォロワーBが破壊される
→Bのラストワードが処理待ち状態
→処理待ち状態にあったAのラストワード処理
→処理待ち状態にあったBのラストワード処理
他の実現手段でもできなくないですが、コールバック処理の考え方で、破壊されるたびにいったんラストワードの関数をコールバック用のリストにため込んでおいて、あとでコールバック関数でその処理をさせる、ってやればいいのか!って考えるとすんなり腑に落ちました。
これもこれで、本当はもっといい処理方法とかあるのかもしれません。あくまで私の知識の範囲内で作り出した想像なので。
新しい発見が多くて楽しいです。勉強が足りていませんし、精進します。
さいごに
早く実現させたくてしょうがないのですが、実現させるための実力が足らず悶々としています。
大会で再現性のある勝利をめざしているので、がんばります。


コメント
更新されているようなのでコメントしてみます。
シャドーバースは最近始めた初心者です。
人工知能で最適手順を編み出すという試みはとても興味深いです。
私はマクロのコードくらいしか書けない素人ですが、シミュレーターを作って学習
させ、その後実際に稼働させるにあたって、一番心折れるのはデータベースの作成だ
と思っています。
あとは今回書かれていた、誘発処理の汎用化。ですか。
正直汎用化は難しいかな、と、今エルフの「アクティブエルフ・メイ」を見ながら
思っています笑
他クラスはほとんどプレイしていないのですが、同様な特殊な効果を複数持つ
カードって多いですよね。
個別判定にするとソースが膨大になって処理速度が落ちるうえ、判定漏れがあり
得ますよね。ゆえに汎用処理を考えておられるのかな、と思います。
汎用化するなら効果のグループ分けからかな、と思いますが、果たして。
コメントありがとうございます!
>シミュレーターを作って学習させ、その後実際に稼働させるにあたって、一番心折れるのはデータベースの作成だ
と思っています。
このあたりは、AlphaZeroや一般の強化学習の考え方を使って、AI同士で対戦することで蓄えていくつもりです。
>誘発効果に関して
その通りですね。実際現在進行形で作成を進めていますが、おっしゃる通り、効果のグループ分けから始めました。カードが多いので丸3日くらいかかりました^^;(とりあえずローテだけ)
効果をグループにわけていくと見えてくるものがあったので、なんとかいけそうな雰囲気が出てきたところです!
処理速度がどこまで耐えられるかは正直わからないので、このあたりは実際にやってみて試行錯誤していく感じでやろうとしています。
長い道のりですが、地道に頑張ります!