
勉強したことや思いついたことなどを忘れないようにメモがてら記事にします。あとは、ゴールまでの道のりが長いので進捗報告(自己管理)として。
目次
強化学習の勉強中
何冊か本を買って勉強しています。
強化学習とは何か
いわゆる人工知能(AI)における機械学習の一種です。囲碁でプロを破ったことで有名なAlphaGOなんかも強化学習に属します(多分)。強化学習は答えがよくわからないものに使われることが多いという認識です。
イメージを例示します。箱の中にネズミとスイッチがあって、スイッチが押されるとエサが出てくる仕組みがあるとします。ネズミはその仕組みは知りません。とりあえず、ネズミは箱の中でエサを求めて、適当に動き回ります。そんな中、たまたまスイッチに体が触れて、エサが出てきます。最初はなんでエサが出てきたのかわかりませんが、色々試行錯誤していくと、「なんだかよくわからんが、スイッチを押すとエサがでるんだ!」と学びます。
これが良く聞く、強化学習のイメージ例です。
対戦ゲームに置き換えると、最初は適当な手を打っていたけれども、強化学習でどんどん学んでいき、勝つための手を打つようになっていきます。
強化学習するとシャドバで何がうれしくなるの?
AIシミュレータを作る目的になりますが、現時点では下記と考えています。
- (AIが賢く学習できていれば)妥当なプレイングのもと、シミュレーションにより試行回数を稼ぐことができ、デッキ相性差が明確になる
- 上記を応用して、環境下で最も勝てるデッキをすばやく構築できる(といいな)
- 上記AIの手筋を見て、プレイングを学ぶことができる
- その結果、世界大会で私が優勝!(やったね!)
似たようなことはこの記事にも書いてあります。


強化学習の勉強の進捗
Twitterでもつぶやきましたが、本を見ながら倒立振子の制御っぽいことを強化学習で組みました。
強化学習の勉強で倒立振子の制御実装。ぶっちゃけ参考書のコード写しただけだけど、それっぽく動いてちょっと感動
強化学習の詳細まではまだよくわかってないけど、なんとなく大まかな概念は掴めてきた気がする
シャドバ適用のとっかかりは、まずはマリガンを強化学習で試してみる感じがいいかな pic.twitter.com/2eFzeJEct9
— あいいろのもち (@mochida_aiiro) May 8, 2020
ただ、細かい理論とかはやっぱり難しくて、なかなか一朝一夕では身につかなさそうです。そこは実際に実装して色々触りながら学んでいこうかと思っています。
今後の進め方
↓の記事のシミュレータにくっつけて、まずはマリガンの方策を強化学習で作ってみようかと思います。

↑の記事では、バリューの高い《鋼鉄と大地の神》ができる確率を計算していますので、デッキを固定して、その確率が強化学習によって高くなるとまずは成功、という形をめざします。(イメージは下図)
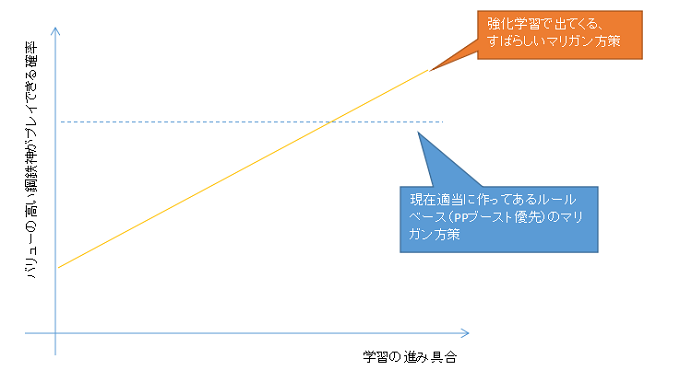
その次のフェーズとしては、上の記事でも書いていますが、現在プレイ方策が適当なので、そのあたりがどうにかならないかなと試してみようと思っています。
構想メモ
全体構成
全体の構成として、今頭の中にあるものを図示化します。
Agentというのが、シャドバをプレイするプレイヤーに相当します。2人プレイゲームなので、二人置いてあります。そして、Agentの中に入っているBrainというのが脳みそです。これがAIに相当します。
このBrainについて、どう運用するのがいいのか現時点でわからないのですが、おそらく、使用するデッキや対戦相手ごとにBrainを用意してあげないといけないのかな、と思っています。
また、上のドラゴンの記事みたいなソリティアプレイだと、Agent2は必要なく、毎ターン《テミスの審判》プレイしている感じでいいかと思います。やりたいことに合わせてカスタマイズしやすいように組みたいですね。
Simulatorはシミュレータです。シャドウバースの対戦を再現できるものを作る必要があります。かなり大変です。新しいカードが追加されるたびに追加実装しなければいけませんし、新しいシステム(WUP環境でいうと「融合」)ができると、それも実装しないといけません。かなり大変です。
状態としてBrainに渡さないといけないもの
完全に個人のメモです。抜けとか気づいたらこの記事のコメントで教えてもらえると助かります。
- 自分の手札の内容(手札バフやコスト低減効果がかかっていたらそれも)
- 自分のデッキ枚数
- 自分のデッキ構築
- 自分の場の状況(フォロワー、アミュレット、フォロワーなら進化状態、攻撃、体力、攻撃可否(攻撃不可or突進状態or攻撃可能状態or攻撃済み)など、アミュレットならカウントダウン状態)
- 自分のプレイしたカードとプレイしたターン
- 自分の破壊されたカード
- 自分の墓地の数
- 自分のライフ
- 自分のPP(現在値、最大値)
- 自分のEP(現在値、最大値)
- 先攻か後攻か
- リーダー付与効果の状態
- 上記のうち、デッキ構築と手札内容を除く、対戦相手の情報
- 対戦相手のクラス
- 対戦相手の手札枚数
多種多様すぎてつらいですね
Brainが行動として渡さないといけないもの
同じくメモです。
- 手札のどのカードをプレイするか?(チョイスや対象選択があればそのパターン分必要)
- 場のフォロワーをどうプレイするか?(相手のフォロワーを殴る?顔にいく?)
- 場のフォロワーを進化するか?(進化時効果で選択があればそのパターン分必要)
- 融合
- ターン終了
報酬をどうするか
メモです。報酬が何かというと、冒頭のネズミの例でいうところのエサのことです。この報酬(エサ)をたくさん得られるように、強化学習はがんばって学習を進めます。
- 勝てば報酬プラス大
- 負ければ報酬マイナス大
- プレイできないものをプレイしようとしたら報酬マイナス小
- 正しくプレイできたら報酬プラス小
今感じている課題になりそうなもの
大きく二つあります。
- シミュレータを作る規模が大きそう
- 機械学習がうまくいくかどうか検討つかない
1に関しては、気合で頑張るしかないです。新パック追加のたびにメンテも頑張る。カード発表直後とかプレリリースに飽きたくらいにちょろっと実装できる形がベスト。
2に関しては、完全に謎です。やってみないとわかりません。AlphaGO の前例があるので、それを勉強して真似ればいいような気もしますが、ゲームが違うのでなんとも言えません。また、完全情報ゲームと不完全情報ゲームで違いがあるかもしれない、という点でも疑問です。あまり不完全情報ゲームでの強化学習例を聞いたことが無いのでよくわかりません。調査は必要そうですね。
日程的な進捗
日程表を少し修正しました。予定を矢印で書いて、実績を色塗りにしました。また、AIの勉強が抜けていたので追加しました。(クリックで画像拡大)
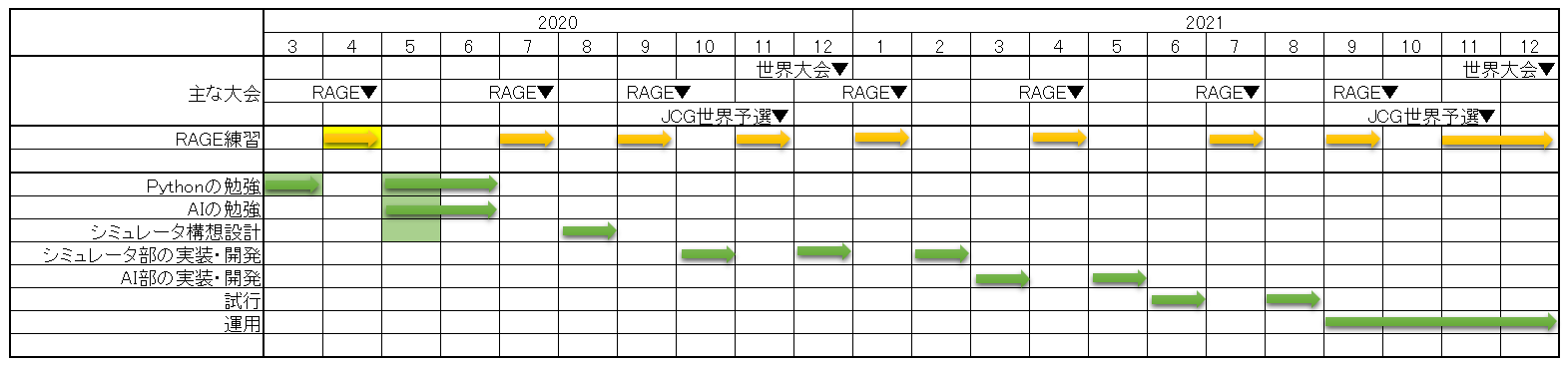
この記事の中段で書いてある構想メモ、という部分が実質上の日程表でいうところの、シミュレータ構想設計に近いので、着手している状態になります。Pythonの勉強としては、別途ドラゴンの託宣枚数検討の記事で書いてあるようにシミュレータを作ったりしたので、それで都度勉強しているということで、実績として色を塗りました。
6月いっぱいまでは、この記事の中段で書いた「今後の進め方」(=いまあるシミュレータにくっつけてマリガン方策を強化学習させる)を実践するなどして、お試しで色々やってみて理解を深める感じかなと思っています。気力があれば前倒しで頑張ります。
一番重いのはやっぱりシミュレータの実装ですね。。シャドウバース複雑やねん。

